|
Background
This article is based on an exercise I found in a textbook, long since forgotten. But it is an interesting and clear example nonetheless. The goal will be to take an Excel spreadsheet and convert it to 3rd normal form. Later I may extend it to Boyce-Codd, which I consider a variation on 3rd normal, and 4th normal.
When designing a database from scratch one would, of course, aim for a properly designed database free from anomalies. Nevertheless, it is very helpful to understand the basics of normalization so that problems can be avoided. Plus, in today's environment much data exists in Excel spreadsheets which usually must be normalized as they are imported into a relational database.
Business Case
Tracking of large industrial equipment such as boilers, feed heaters, etc. in chemical plants in the South. Each piece of equipment has a composite primary key consisting of the plant name and equipment type. In other words something like styrene feed heater.
Normal Forms
There are five normal forms, three of which we will consider in this article. They are cumulative in the sense that a table that satisfies 2nd normal form also satisfies 1st and so on. I will cover 1st in this page. 2nd and 3rd in future pages.
1st normal form
To be in 1st normal form a table must meet the following conditions:
All rows are unique
All cells are atomic
There are no repeating groups
All columns have a unique name
The order of rows and columns does not matter
Original spreadsheet
Below is the original spreadsheet. Plant name and eqpt name form a composite identifier for each row. This spreadsheet contains a violation of the 1st normal form rules.
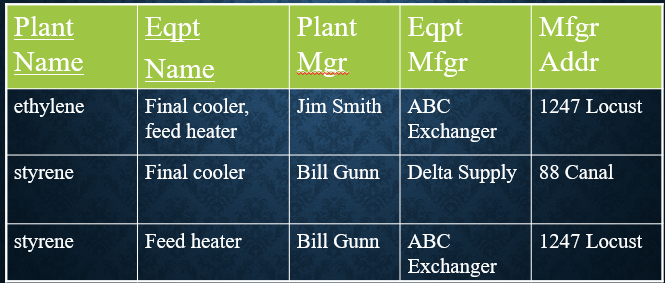
The problem is that not all cells are atomic. The 2nd column in the 1st row has two entries. This violates the rules above for 1st normal form.
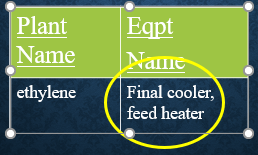
How do we correct this issue? On the next page we will show the design in correct 1st normal form.
Continue
to page 2 - 2nd normal form
Submit the form below to be notified of new articles or other
database design resources made available...
Learn more about our Microsoft Access courses..
|



